罗福莉解密MiMo降本底牌:预填充注意力计算量降至10层全局GQA级别

快链头条 2026-05-27 22:17:56

据动察 Beating 监测,在自研大模型 MiMo-V2.5 系列实施 API 永久性降价后,小米大模型团队负责人罗福莉在 X 平台公布了算法降本机制。
罗福莉透露,在 API 价格对齐 DeepSeek 后,小米的高负载推理引擎仍能保持盈亏平衡。成本降低主要来自混合注意力架构与层次化 KV 缓存优化。
针对缓存命中(Cache Hit)成本降低 99% 的设计目标,小米推理框架实现了针对滑动窗口注意力 SWA 的层次化 KV 缓存优化。生产测试显示,层次化优化将缓存的 token 容量提升至 5 倍,降低了 80% 的缓存成本。结合全局注意力模块之间的缓存读取重叠(Cache Read Overlap)技术,系统进一步压低了缓存命中的实际开销。
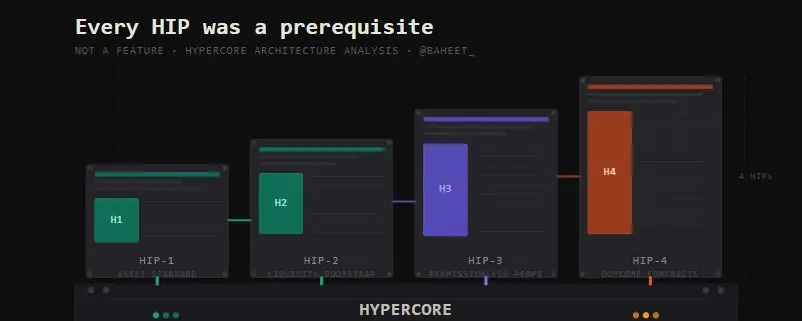
对于基础输入与输出成本削减 60% 至 80% 的原因,罗福莉归功于模型引入的 1:7 层间稀疏比,即全局注意力(GA)与滑动窗口注意力(SWA)的层数比为 1:7 。在长文本预填充(Prefill)阶段,60 层 SWA 仅计算局部滑动窗口,这使得拥有 70 层的 MiMo-V2.5-Pro 模型的整体注意力计算量,仅相当于一个 10 层的传统全局 GQA 模型。超低计算负载降低了原始推理成本,在调价前曾为小米预留了 2 至 3 倍的利润空间。因此,降价属于结构性降本的体现,而非亏本竞争。
罗福莉表示,低成本的推理服务有利于激发终端智能需求。大模型企业应当避免盲目的价格战,通过算法与推理系统的底层协同设计,将实际运行开销控制在盈亏平衡线以下。
快链头条登载此文本着传递更多信息的缘由,并不代表赞同其观点或证实其描述。
文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。
投资有风险,入市须谨慎。本资讯不作为投资理财建议。