【英文长推】浅析三种评估 AI Agent 的方法:有何利弊?
评估 AI Agent 主要有 3 种方法:1)自动基准测试:AI 单元测试。通用基准(MMLU、ARC、HumanEval)有助于衡量人工智能的性能。优点:快速、一致的反馈;易于跟踪改进情况。缺点:可被「戏弄」;并不总是反映现实世界的使用。 2)人工反馈:OG 方法。优点:真实世界验证;捕捉细微问题;直接用户对齐;更适合主观任务。缺点:昂贵且缓慢;难以扩展;评估者之间不一致;容易受到人为偏见的影响。3)模型作为评判者:将其视为获取专家意见,但通过 LLM 实现自动化。优点:可扩展;标准一致;比人工反馈更快。缺点:继承模型偏见;能偏向某些风格;受模型能力限制。 一些很酷的新工具使评估更容易:Weights & Biases 刚刚发布了 Weave,一个完整的评估工具包,使跟踪和改进 Agent 变得更简单;LangChain 的 LangSmith 是一款用于调试 Agent 的工具;LlamaIndex 为 RAG 带来特定指标。【原文为英文】\n原文链接
温馨提示:
快链头条登载此文本着传递更多信息的缘由,并不代表赞同其观点或证实其描述。
文章内容仅供参考,不构成投资建议。投资者据此操作,风险自担。
提示:投资有风险,入市须谨慎。本资讯不作为投资理财建议。
7*24小时快讯
热门资讯

熊市生存指南:L2 还有哪些潜在空投机会?
2022-05-13 12:47

目前的市场环境能否支撑比特币再次走牛?
2022-04-19 18:10

除了Coinlist,你还应该知道的打新平台
2022-03-01 13:37
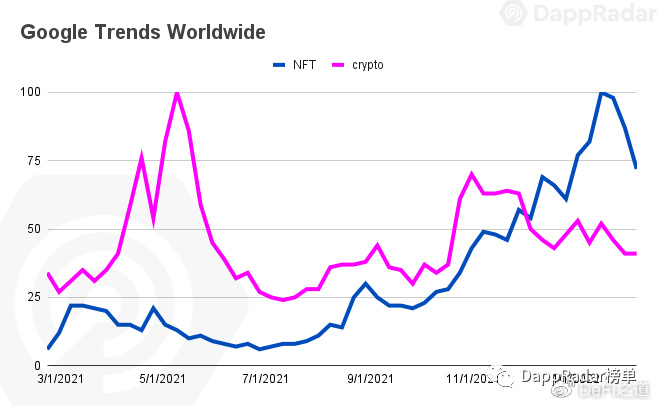
鲸鱼报告:解密知名NFT收藏家的交易模式
2022-02-28 16:56
最新活动

Solana Breakpoint 2025
2025-12-11 08:00

Taipei Blockchain Week
2024-12-23 18:33

2025 Singapore Fintech Festiva
2024-12-23 18:33

2025 Blockchain Futurist Conference
2024-12-23 18:33